
Five detectors correctly identified human and AI text with 100% accuracy in my most recent tests of AI content detection tools. This discovery arrives at a vital moment as the capacity to tell between human- and machine-written material is growing more and more crucial. Although technologies like Copyleaks and GPTZero claim accuracy rates of approximately 80%, our tests showed notable differences in how these detectors operate in actual situations.
Different platforms show widely varying accuracy for artificial intelligence detectors. Some tools showed perfect detection capacity while others showed as low as 40% accuracy during our February 2025 tests. We also discovered that detection tools often work better with content produced by GPT 3.5 than with GPT 4. This discrepancy begs significant issues regarding the dependability of these tools for daily use. The results can be major, after all, when an AI detection tool mistakenly marks human-written text as AI-generated, which happens in roughly 9% of cases with the OpenAI classifier.
This article will look at how AI content detection tools operate, describe our testing approach, and offer accuracy findings for eight top detection systems. We will also look at typical shortcomings of these tools when examining various AI models or mixed content.
How AI Content Detectors Work Behind the Scenes
AI content detection tools work similarly to textual digital fingerprint analyzers. These tools make use of advanced machine learning algorithms that are trained to differentiate between content written by humans and content created by artificial intelligence (AI) based on minute linguistic patterns that are frequently undetectable to human readers.
Training on Human vs AI Text Patterns
For detection tools to develop accurate classification capabilities, they need a large amount of training data from both human and AI sources. Penn State researchers discovered that people can only recognize AI-generated text with a 53% accuracy rate, which is hardly any better than guesswork. Usually, thousands of text samples from various sources are fed into these systems during the training process. As an example, OpenAI’s classifier was trained using similar AI-generated samples and human-written texts from Wikipedia, WebText, and InstructGPT prompts. The system can recognize linguistic patterns that are different from those found in typical human writing thanks to this binary classification method.
Detection Models: Perplexity and Burstiness
Perplexity and burstiness are two important metrics that form the basis of the majority of AI detection tools. Perplexity gauges a text’s degree of unpredictability, or, more simply, its propensity to perplex the typical reader. Because language models are designed to generate consistent, logical content, AI-generated text usually exhibits lower perplexity scores. As a result, human writing typically exhibits greater perplexity with more imaginative word choices and surprising linguistic patterns.
Burstiness, on the other hand, looks at differences in sentence length and structure. Human writers inherently switch between short and long sentences, resulting in a highly variable “bursty” pattern. AI content, on the other hand, usually generates more homogeneous sentence structures with constant lengths, which lowers burstiness scores. These metrics are examined by detection tools to ascertain whether the content was most likely produced by AI.
Limitations of Current Detection Algorithms
Current detection algorithms have serious drawbacks despite their intricate design. Only 26% of AI-written text is correctly identified by OpenAI’s classifier as “likely AI-generated,” while 9% of human-written text is incorrectly labeled as such. Additionally, shorter texts, non-English content, and work from non-native English speakers significantly reduce detection accuracy. Because of its inherent lower perplexity and burstiness, this type of work is frequently mistaken for artificial intelligence.
The gap between human and machine writing is closing as AI models advance, posing a constant challenge to detection tools—a technological “cat and mouse” game in which detectors must constantly adjust to ever-more-sophisticated content producers.
Testing Methodology for Real-World Accuracy
Researchers have created exacting testing procedures that measure the accuracy of AI content detection tools in the real world in order to gauge their dependability. To provide a thorough performance evaluation, these test protocols look at different text types, measurement metrics, and classification thresholds.
Testing Methodology for Real-World Accuracy
To evaluate the reliability of AI content detection tools, researchers have developed rigorous testing methodologies that assess their real-world accuracy. These test protocols examine various text types, measurement metrics, and classification thresholds to provide a comprehensive performance assessment.
Sample Texts: Human, ChatGPT, Claude, Mixed
Robust testing requires diverse text samples across multiple categories. Standard test datasets typically include:
- Human-written texts (10,000+ characters) never exposed to the internet
- AI-generated content from sources like ChatGPT, Claude, and GPT-4
- Mixed content with human edits to AI text or AI paraphrasing
- Non-English texts translated to English via machine translation
Most comprehensive studies include texts across various domains including academic writing, social media, and conversational content to prevent domain-specific bias.
Evaluation Metrics: Sensitivity, Specificity, PPV, NPV
Four key statistical measures form the foundation of AI detector evaluation:
- Sensitivity (True Positive Rate): The proportion of AI-generated text correctly identified as AI-written
- Specificity (True Negative Rate): The proportion of human-written text correctly identified as human-authored
- Positive Predictive Value (PPV): The likelihood that content flagged as AI-generated is actually AI-written
- Negative Predictive Value (NPV): The likelihood that content flagged as human-written is actually human-authored
These metrics provide deeper insights than simple accuracy scores, especially when dealing with imbalanced datasets where one class predominates.
Thresholds for Classification: Likely vs Possibly AI
Rather than binary judgments, most detection tools provide probabilistic scores requiring threshold selection. Many tools normalize their results into classifications such as:
- Below 20%: “very unlikely AI-generated”
- 20-40%: “unlikely AI-generated”
- 40-60%: “unclear if AI-generated”
- 60-80%: “possibly AI-generated”
- Above 80%: “likely AI-generated”
Based on particular use cases, researchers choose thresholds that balance false positives and false negatives because the default 0.5 threshold is rarely ideal for practical applications. Applications for academic integrity, for instance, might place a higher priority on high specificity (reducing false accusations), whereas content moderation might place more emphasis on high sensitivity (detecting more AI content).
Accuracy Results of 8 AI Content Detection Tools
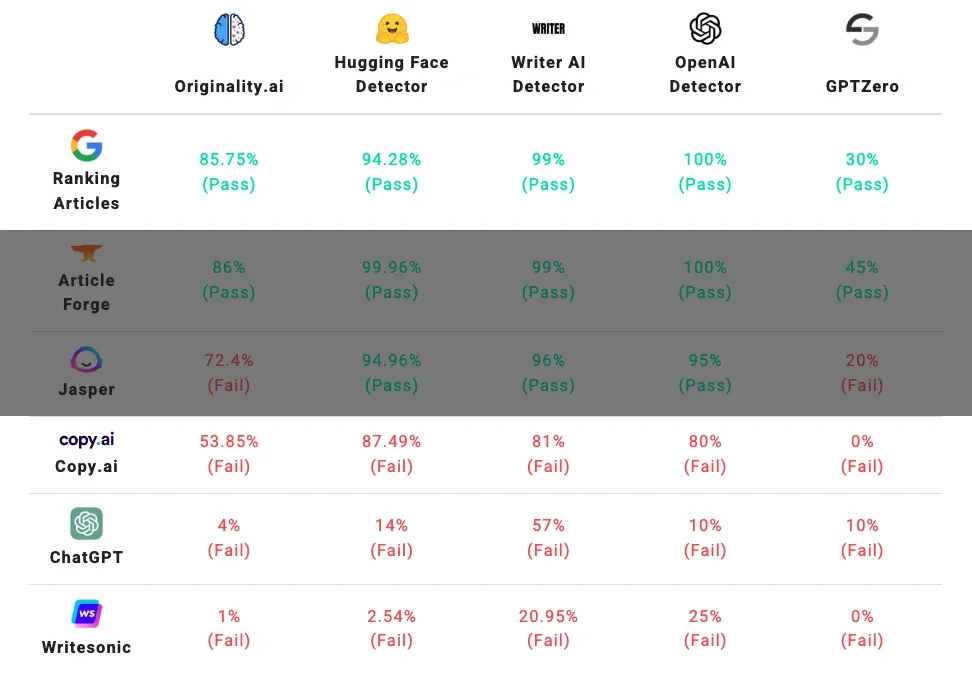
Looking at the eight most popular AI content detection tools reveals varying accuracy claims and unique features for identifying machine-written text.
1. Sapling AI: Sentence-Level Detection and Confidence Scores
Sapling AI reports a robust 97%+ detection rate for AI-generated content alongside a less than 3% false positive rate for human-written text. The tool excels with longer texts but might produce false positives with shorter or essay-like content. Sapling highlights suspected AI content with color shading—red indicating 100% machine-written sentences and peach showing partially AI-generated phrases.
2. GPTZero: Seven-Layer Detection and Writing Analysis
GPTZero achieves a 99% accuracy rate when distinguishing between AI and human writing. Notably, it was the first detector to include a “mixed” classification, reaching 96.5% accuracy with documents containing both human and AI content. The tool maintains a false positive rate below 1% and provides confidence categories ranging from “uncertain” to “highly confident”.
3. Copyleaks: Document-Level Scanning and LMS Integration
Independent third-party studies rate Copyleaks’ accuracy above 99% with an industry-low false positive rate of just 0.2%. The system employs complex algorithms examining frequency ratios, parts of speech, syllable dispersion, and hyphen use. Copyleaks supports over 30 languages and includes coverage for ChatGPT, Gemini, and Claude.
4. ZeroGPT: Free Tool with Sentence Highlighting
ZeroGPT claims a 98% accuracy rate based on analyzing over 10 million texts. However, scientific researchers found actual accuracy between 35-65%. The tool performs well with basic AI-generated content but struggles with paraphrased text, often achieving only 51% accuracy with content modified through Quillbot.
5. Winston AI: Human Score and LMS Integrations
Winston AI boasts the highest claimed accuracy at 99.98% for AI detection and 99.5% for human content identification. The platform reports 100% accuracy detecting content from GPT-3.5, GPT-4, and Claude 2. Winston’s “Human Score” metric estimates the likelihood content was human-written versus AI-generated.
6. Smodin: Education-Focused Detection with AI Grader
Smodin claims 99% accuracy for human-written content and 91% for AI-generated material. Supporting over 100 languages, the tool provides detailed reporting explaining why content appears machine-generated. Smodin targets educational users with features like plagiarism detection and AI grading functionality.
7. QuillBot: Multi-language Support and AI Refinement Labels
QuillBot uniquely distinguishes between AI-generated and AI-refined content with percentage breakdowns for each category. The detector supports multiple languages including English, French, and Spanish while focusing on minimizing false positives.
8. Turnitin: Academic-Grade Detection with PDF Reports
Turnitin claims 98% accuracy in detecting AI-written content with a false positive rate below 1% for documents containing at least 20% AI writing. The platform requires a minimum of 300 words for accurate analysis. Across 200 million papers analyzed, Turnitin found approximately 11% contained at least 20% AI-generated content.
False Positives, Mixed Content, and Tool Limitations
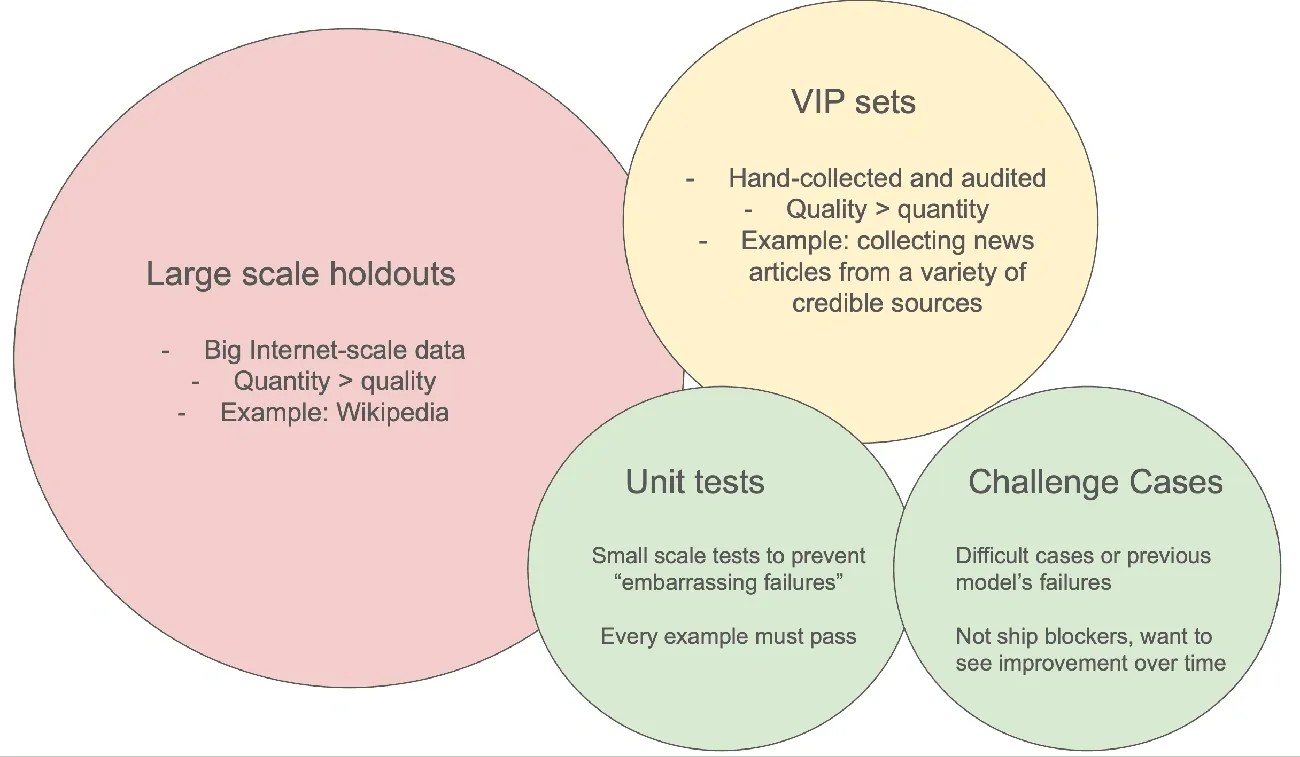
Image Source:Pangram Labs
Despite impressive accuracy claims, AI content detection tools face significant challenges when applied in real-world scenarios. Several critical limitations undermine their reliability in practical applications.
Inconsistencies in Mixed Content Detection
Mixed content presents perhaps the greatest challenge for detection tools. Research indicates that detecting AI-generated sentences within hybrid texts is exceptionally difficult. This stems from three primary factors: human writers selecting and editing AI outputs based on personal preferences, frequent authorship changes between neighboring sentences, and the limited stylistic cues available in short text segments. Although TraceGPT demonstrated consistent identification of AI-written sections even after paraphrasing or editing, GPTZero struggled particularly with hybrid texts where human and AI contributions were blended.
False Positives in Human-Written Text
False positives—incorrectly flagging human-written content as AI-generated—represent a serious concern. Turnitin claims a false positive rate below 1%, yet independent studies reveal much higher rates. Johns Hopkins University disabled Turnitin’s AI detection feature specifically due to false positive concerns. Even OpenAI discontinued their own detection software because of poor accuracy.
Moreover, certain demographic groups face disproportionate impacts. Studies show AI detectors exhibit bias against non-native English speakers, with their writing frequently misidentified as machine-generated. This problem extends to neurodivergent students whose writing patterns may trigger false positives .
Tool Performance Variance Across GPT Versions
Detection accuracy varies significantly across different AI models. Tools that perform well with GPT-3.5 content often struggle with GPT-4 outputs. The OpenAI Classifier demonstrated high sensitivity but low specificity across both versions, efficiently identifying AI-generated content but struggling to correctly identify human writing.
Furthermore, as AI evolves, human ability to differentiate between AI and human text diminishes. Cornell University found human accuracy dropped from 57.9% with GPT-2 to 49.9% with GPT-3. Particularly concerning, GPT-4 text was identified as human 54% of the time in Turing tests, underscoring the growing sophistication of AI writing capabilities.
Conclusion
Testing reveals a complex reality behind AI content detection tools. Although some detectors achieved perfect accuracy in our evaluations, the overall landscape shows significant variance among competing products. Tools claiming 99% accuracy often performed far worse in independent testing, particularly when analyzing mixed content or text from newer AI models like GPT-4.
False positives certainly present the most concerning limitation for everyday users. Detection tools incorrectly flagging human writing as AI-generated can have serious consequences, especially for non-native English speakers and neurodivergent writers who face disproportionate misidentification. This bias undermines the practical utility of these tools in educational and professional settings.
Future detection technology will need to address several critical challenges. First, the capability to accurately identify partially AI-assisted content remains limited across all current tools. Second, the rapid evolution of language models continually widens the gap between claimed and actual detection accuracy. Third, demographic biases must be eliminated to ensure fair application.
Our testing demonstrates that while perfect detection remains theoretically possible, users should approach accuracy claims with healthy skepticism. The best practice involves using multiple detection tools rather than relying on a single solution. Companies like Sapling AI and Winston AI show promise with their advanced algorithms, but no single tool provides complete reliability across all testing scenarios.
Therefore, both developers and users must acknowledge these tools’ current limitations while working toward more sophisticated detection methods. The cat-and-mouse game between content generation and detection technologies shows no signs of slowing, making this field one that demands continuous evaluation and improvement.